





Pentaho Metadata Model: Joining two fact tables
My Suggestions
Tutorial Details
- Knowledge: Intermediate (To follow this tutorial you should have good knowledge of the software and hence not every single step will be described)
- Tutorial files can be downloaded here
The Pentaho Metadata layer is amazing: It allows end users to build reports without actually writing a line of SQL. Database and/or table changes can be easily accommodated by only changing the references in the metadata model and hence reports, dashboards, etc stay unaffected.
While it is fairly easy to set up a metadata model with one fact table (and some dimensions), using more than one fact table (which also might have different granularity) posses a challenge for many users. Is it really possible to do this in PME (Pentaho Metadata Editor)? The answer is yes, although in the current version I don't consider it to be an ideal solution and I hope that in future it will be possible to visually design this in the relationship diagram.
In this session I'd like to discuss the approach of integrating more than one fact table into your metadata model.
The data
We will base our example on this simple schema:
CREATE SCHEMA
metadatatest
;
CREATE TABLE
metadatatest.fact_sales
(
date_id INT(255),
location VARCHAR(70),
sales INT(255)
)
;
INSERT INTO
metadatatest.fact_sales
VALUES
(1,"London", 34),(1,"Manchester", 44),(2,"London",24),(2,"Manchester",35),(2,"Bristol",34),(3,"London",53)
;
CREATE TABLE
metadatatest.fact_stock
(
date_id INT(255),
location VARCHAR(70),
aisle VARCHAR(70),
stock INT(255)
)
;
INSERT INTO
metadatatest.fact_stock
VALUES
(1,"London","aisle 1", 34),(1,"London","aisle 2", 44),(1,"London","aisle 3", 234),(1,"Manchester","aisle 1", 44),(1,"Manchester","aisle 2", 344),(2,"London","aisle 1",24),(2,"London","aisle 2",25),(2,"Manchester","aisle 1",35),(2,"Bristol","aisle 1",34),(2,"Bristol","aisle 2",324),(3,"London","aisle 1",53)
;
CREATE TABLE
metadatatest.dim_date
(
date_id INT(255),
date DATE
)
;
INSERT INTO
metadatatest.dim_date
VALUES
(1,"2011-01-01"),(2,"2011-01-02"),(3,"2011-01-03")
;
What we want to achieve is basically getting the same result out of PME as with following summary query:
SELECT
*
FROM
(
SELECT
date,
SUM(sales) AS sales
FROM
metadatatest.fact_sales s
INNER JOIN
metadatatest.dim_date d
ON
s.date_id=d.date_id
GROUP BY 1
) a
INNER JOIN
(
SELECT
date,
SUM(stock) AS stock
FROM
metadatatest.fact_stock s
INNER JOIN
metadatatest.dim_date d
ON
s.date_id=d.date_id
GROUP BY 1
) b
ON
a.date=b.date
;
Open your favourite SQL client and run these queries.
The aggregation query gives back following result:

Metadata Model
So let's start creating our Metadata model: One thing to keep in mind is that our two fact tables have different granularity. In PME you cannot just import them as physical tables, then place them both in a business model and create a relationship between them: Such a model will not return correct aggregations.
The critical element is: You basically have to specify the "physical tables" as join of your star schemas. What I mean by this is that you write a query that joins your fact table with all the dimension tables. This query returns a result set which can act as a "physical table" in PME (although the wording "physical table" doesn't make sense in the context, it is more a derived table or better said a view).
In our case we will have two derived tables. These two derived tables have to have the same granularity:
- Sales Table: a join of the fact_sales table with the date dimension
- Stock Table: a jon of the fact_stock table with the date dimension, aggregated by date and location
- Open PME and create a new domain.
- Set up your database connection to the just created schema.
- Reference our two fact tables.
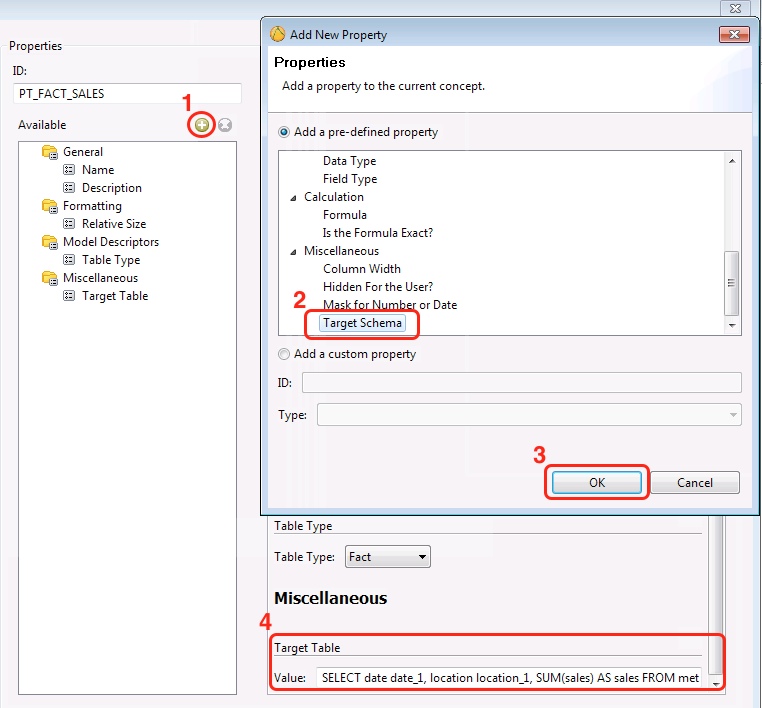
- Double click on the fact_sales table. The properties window will be shown.
- Click on the green plus icon in the Properties section and add the Target Table property. Click OK.
- Fill out the Target Table field with this query:
SELECT date date_1, location location_1, SUM(sales) AS sales FROM metadatatest.fact_sales s INNER JOIN metadatatest.dim_date d ON s.date_id=d.date_id GROUP BY 1, 2).
Note we gave the date and location columns intentionally different names so that they are later on easier to distinguish from the other fact table's fields. - Click OK to close the Properties window.
- Double click on the fact_stock table. The properties dialog will be shown.
- Click on the green plus icon and add the Target Table property. Click OK.
- Fill out the Target Table field with this query: Fill out the Target Table field with this query:
SELECT date, location, SUM(stock) AS stock FROM metadatatest.fact_stock s INNER JOIN metadatatest.dim_date d ON s.date_id=d.date_id GROUP BY 1, 2 - Click OK to close the Properties window.
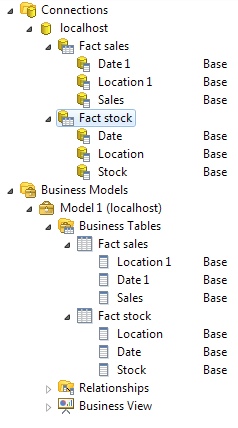
- Create a business model and drag and drop the physical tables into the Business Tables folder. Your Tables should now look like this (as you can see they have same granularity now):
- Next create the relationship: Drag and drop the business tables onto the canvas, hold down the CTRL key, mark the first table and then the second one and right click. Choose Add Relationship ...
- Set Relationship to N:N and Join type to Inner.
- Tick Complex Join? and copy following lines into the Complex Join Expression:
AND([BT_FACT_SALES_FACT_SALES.BC_FACT_SALES_DATE_1]=[BT_FACT_STOCK_FACT_STOCK.BC_FACT_STOCK_DATE]; [BT_FACT_SALES_FACT_SALES.BC_FACT_SALES_LOCATION_1]=[BT_FACT_STOCK_FACT_STOCK.BC_FACT_STOCK_LOCATION]) - Click OK.
- Save the model. Now we are ready to test if it is working properly.
- Click on the Query Editor icon. Select Date, Sales and Stock as columns, then press the Play button. Examine the result: It returns exactly the same values as the SQL query we ran at the beginning of the tutorial. If you are curious you can as well click on the SQL icon and you can see which SQL query PME created under the hood.


My Suggestions
It is important to provide feedback to the developers of such great products as the PME. I can see in my daily work what a big impact this product makes. I can see end users who can finally create reports to their liking without running to a report designer and waiting for the result to be delivered. When you create a lot of reports you don't have to worry if a database change results in having to change all the references in all your reports. From my point of view a metadata model is a key element in a BI system.
In the beginning of this article I already mentioned that I don't think the current way of setting up this solution is ideal. The reason for this is that it breaks the concept. Normally you would define the relationships between tables in a business model and the SQL would be automatically created. When dealing with more than one fact table (with different granularity), you have to use a completely different approach and write a SQL query yourself by joining your fact table all dimension tables and only then you can create the relationship diagram.
It's not a problem of "Oh I have to write a query", but it is more a problem of consistent approach. I'd really welcome if we could design the complete model in a relationship diagram (consistant approach) instead of hacking the shortcomings by providing SQL queries. I think the user experience would be much better.
I set up a JIRA case on the Pentaho website to, please show your support by voting for it and we might see this feature implemented soon!
At the end of the session I'd like the thank Will for his great support!







0 comments:
Post a Comment