





Pentaho Kettle Parameters and Variables: Tips and Tricks
This blog post is not intended to be a formal introduction to using parameters and variables in Pentaho Kettle, but more a practical showcase of possible usages.
Please read my previous blog post Pentaho Data Integration: Scheduling and command line arguments as an introduction on how to pass command line arguments to a Kettle job.
When I mention parameters below, I am always talking about named parameters.
Parameters and Variables
Definitions upfront
Named Parameter: “Named parameters are a system that allows you to parameterize your transformations and jobs. On top of the variables system that was already in place prior to the introduction in version 3.2, named parameters offer the setting of a description and a default value. That allows you in turn to list the required parameters for a job or transformation.” (Source)
Variable: “Variables can be used throughout Pentaho Data Integration, including in transformation steps and job entries. You define variables by setting them with the Set Variable step in a transformation or by setting them in the kettle.properties file. [...] The first usage (and only usage in previous Kettle versions) was to set an environment variable. Traditionally, this was accomplished by passing options to the Java Virtual Machine (JVM) with the -D option. The only problem with using environment variables is that the usage is not dynamic and problems arise if you try to use them in a dynamic way. Changes to the environment variables are visible to all software running on the virtual machine. [...] Because the scope of an environment variable is too broad, Kettle variables were introduced to provide a way to define variables that are local to the job in which the variable is set. The "Set Variable" step in a transformation allows you to specify in which job you want to set the variable's scope (i.e. parent job, grand-parent job or the root job).” (Source). “
Example
Let’s walk through this very simple example of using parameters and variables. I try to explain all the jobs and transformations involved. The files are also available for download here. You can find the following files in the folder intro_to_parameters_and_variables.
jb_main.kjb

In this extremely simple job we call a subjob call jb_slave.kjb. In this case, we defined hard coded parameter values in the job entry settings. Alternatively, to make this more dynamic, we could have just defined parameters in the job settings.
jb_slave.kjb
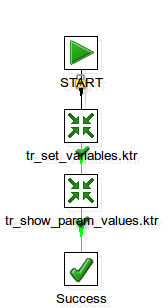
This subjob executes the transformations tr_set_variables.ktr and tr_show_param_values.ktr. In this case, in order to access the parameter values from the parent job, we defined the parameters without values in the job settings:
Note: This is just one of the ways you can pass parameters down to the subprocess.
tr_set_variables.ktr
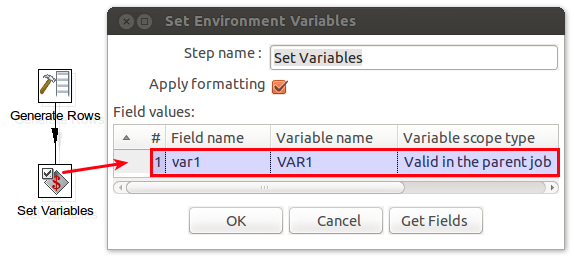
This transformation sets a variable called var1 with scope Valid in parent job so that successive processes can make use if it. In this case the values originate from a Generate Rows step for demonstration purposes; in real world examples you might read in some values from a file or a database table.
tr_show_param_values.ktr
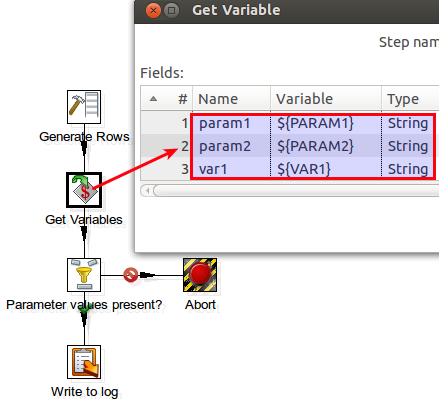
The main transformation has the sole purpose of writing all the parameter and variable values to the log. We retrieve the parameters and variable by using a Get Variables step. We also check if a value is present by using a Filter Rows step. In case one value is missing, we Abort the transformation, otherwise the values are written to the log.
There is no need to set the parameter names in this transformations; there is an advantage though if you do it:
Missing parameter values will be properly displayed as NULL, which makes it a bit easier to check for them.
If you don't define them in the transformation settings, missing parameter values will be displayed as ${PARAMETERNAME}.
Important: Variables coming from tr_set_variables.ktr MUST NOT be listed in the Parameter tab in the Transformation Settings as this overrides the variable.
Making Parameters available for all subprocesses in an easy fashion
As you saw above, defining the parameters for each subprocess just to be able to pass them down can be a bit labour intensive. Luckily, there is a faster way of doing just this:
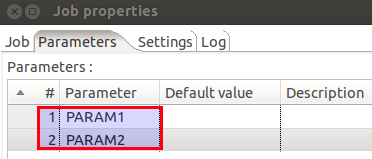
- In the main job specify the parameters that you want to pass in in the Job Settings:
This way parameters and their values can be passed in from the command line in example. - Right after the Start job entry use the Set Variables job entry. Specify the variable names, reference the parameters you set up in step 1 and set the scope to Valid in the current job.
- There is no need to specify any parameters/variables in any of the subprocesses.


To see how this is working, run jb_main.kjb in the passing_down_parameters_in_an_easy_fashion folder (part of the provided examples).
What if I still want to be able to run my subprocess independently sometimes?
You might have some situations, when you have to run the subprocess independently (so in other words: You do not execute it from the parent/main job, but run it on its own). When we pass down parameters or variables, this can be a bit tricky and usually it just doesn’t work out of the box. Luckily, there is a way to achieve this though:
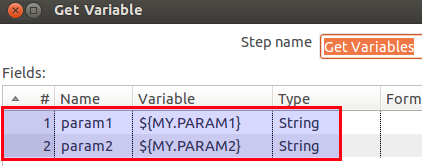
- In the subprocess, specify the parameter that you want to be able to pass in. In our example (which is based on the previous example), we modified the transformation tr_show_param_values.ktr and added following parameters to the Transformation Settings:
We also amended the Get Variables step to make use of these parameters:
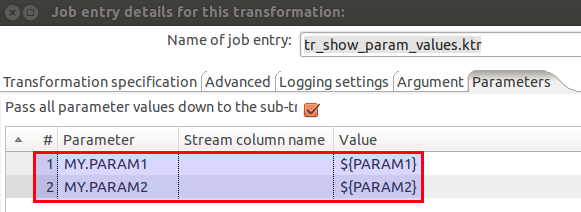
This way, we can already run this transformation on its own. Now we only have to adjust the parent job so that we can run it from there as well. - In the parent job, in the Job or Transformation job entry settings, go to the Parameters tab and tick Pass all parameter values down to the sub-transformation/sub-job. Next, as the Parameter set the name of the parameter you defined in the subprocess. As the Value define the variable that you want to pass down: ${variable}. This assumes that this variable was set beforehand by some Set Variables job entry/step.
In our case, we modified transformation job entry in the job jb_slave.kjb and added following mapping to the job entry settings in the Parameters tab:

A sample for this setup is provided in the mulitpurpose_setup_allow_individual_execution_of_subprocesses folder.
Closing remarks
Using parameters and variables in Kettle jobs and transformations allows you to create highly dynamic processes. I hope this tutorial shed some light onto how this can be achieved.







0 comments:
Post a Comment