





Today I came across a special use case for an outer join. I was planning to set up an ETL process that imports yesterday's revenue summary by summarizing the input of two tables.
The main problem was, that we might not have made any revenue yesterday at all, or there might be only revenue in one table but not the other.
Basically, if revenue figures exist in both tables, the process would be following:
- input data from table 1: date, service name, revenue_cars
- input data from table 2: date, service name, revenue_carparts
- join the tables, so that the output looks like: date, service name, revenue_cars, revenue_carparts
The problem is, as mentioned, that not every day data will be available in both tables. So I would have to implement a logic like this one:
- IF input data table 1 NOT EMPTY AND input data table 2 EMPTY THEN output only data of table 1.
- IF input data table 2 NOT EMPTY AND input data table 1 EMPTY THEN output only data of table 2.
- IF input data table 1 NOT EMPTY AND input data table 2 NOT EMPTY THEN JOIN everything and output it.
All this can be achieved by using a FULL OUTER JOIN.
So your process in Kettle should be as follows:
- Drag and drop two "table input" steps into the working area and define the settings. Our query looks like this:For table1:GROUP BY 1,2
SELECT
date,
service_name,
COUNT(*) AS count
FROM
table1
For table2:
SELECT
date,
service_name,
COUNT(*) AS count,
SUM(rev) AS rev_sum
FROM
table2
GROUP BY 1,2 - For each of them add a sort step and connect them with the table input. Make sure you sort the relevant fields in ascending order (in our case this is date and service_name).
- Drag and drop a Join step on the working area, connect them with the two sort steps and then define the two sort steps as input.
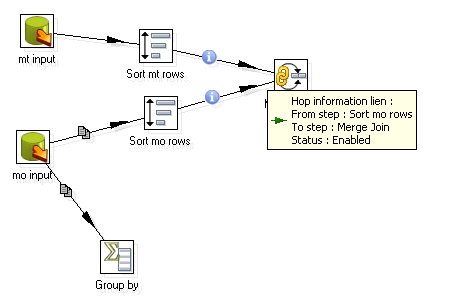
In this screenshot you can also see a Group By Step. This one is not in use at all. But in case you want to check if there is any output of this step, the group by step has an option called "Always give back a result row", which, when ticked, will set the aggregation to 0 (Zero). This might be useful in some cases. This is different to the Detect Empty Stream step, which only gives back a completely empty row in any case.
Ok, so now we have the FULL OUTER JOIN working. Have a look at the output by exporting it into a text or Excel file. You will see that in case both result sets didn't match, the number fields (count and rev_sum) are blank. As we want to use these fields later on in calculations, we have to assign a default value in case the number field is null.
Insert a If field value is null step, connect it to the previous step and double click on it afterwards. Tick "Select fields" and in the fields table add count and rev_sum and assign a default value of 0 (Zero) to them.
Another thing that you will also have recognized by looking at the output is that we have now two additional fields: service_name_1 and date_1.
So now we have to do a check. In case there are matching values in both results, both
- date and data_1 and
- service_name and service_name_1
will be populated. If it is not in both, only one of them will be populated. So we are going to create a new variable called service_name_new and date_new that are going to replace the old ones in a "Modified Java Script Value" Step. Drag and drop this step on the working area and connect it with the Merge Join Step. Douple click on the Modified Java Script Value Step and insert following script plus tick "Compatibility Mode":
if (service_name.isNull()) {
var service_name_new=service_name_1;
}
else
{
var service_name_new=service_name;
}
if (date.isNull()) {
var date_new=date_1;
}
else
{
var date_new=date;
}
Add service_name_new and date_new as output fields and define the type. Then add a Select values Step and add all the fields, but not service_name_1, service_name, date, date_1. Add another step to export it into Excel in example. Our whole process should look like this now (please ignore that some connection have the copy sign, this will not be the case with your process):

In this small tutorial we have now set up a nicely working FULL OUTER JOIN. I hope that you can implement this in your ETL processes now without any problems.







0 comments:
Post a Comment