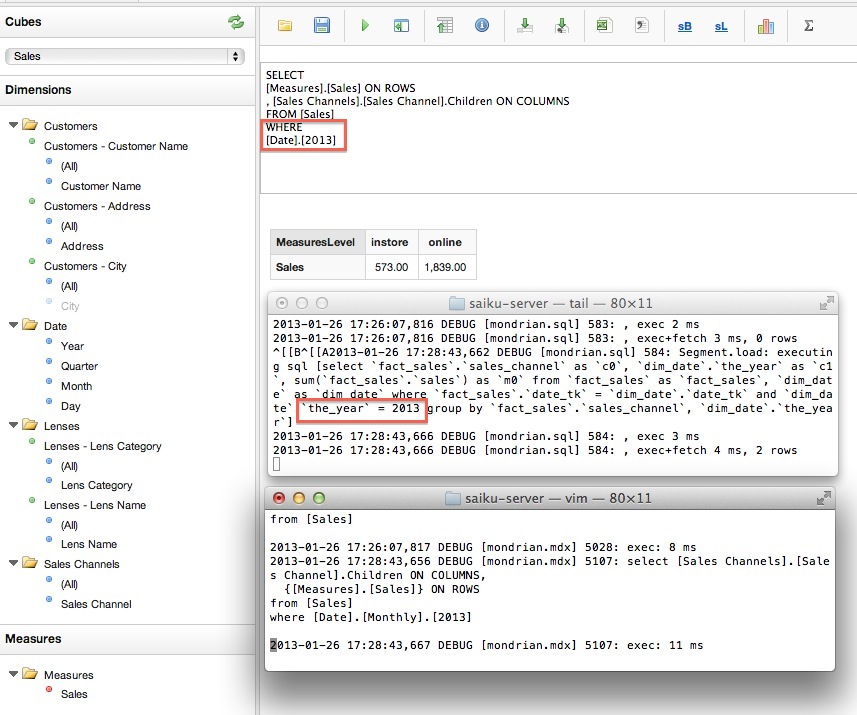
In this article we will take a look at how to create some complex routing conditions for a Pentaho Data Integration (Kettle) job.
Out-of-the-box Kettle comes already with several easy to use conditional job entries:
In some situations though you might need a bit a bit more flexibility, this is when the JavaScript job entry comes into play:

This one is found in the Scripting folder. The name used in the configuration dialog of this particular step is from my point of view better actually better suited: Evaluating JavaScript.
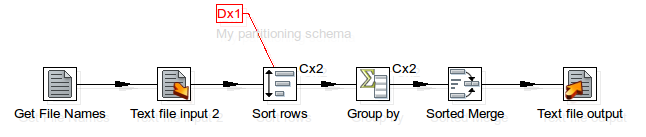
We will look at a very trivial example:
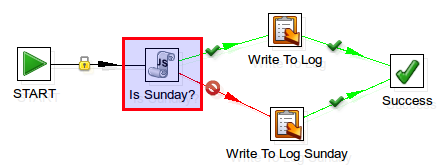
In this job flow we only want to execute the Write To Log Sunday job entry if the day of the week is a Sunday. On all other days we want to execute the job entry Write to Log.
The Evaluating JavaScript job entry is configured as shown in the screenshot below:

Note that you can write multiple lines of code, but you must make sure that the return value is a boolean value!
In case you want to create this example yourself, please find below the JavaScript code:
var d = new Date();
var dof = d.getDay();
dof == 6 ? true : false;
Running this ETL process on a Wednesday will show the following in the log:

As you see it is rather simple creating more complex conditions and the bonus is that you can make use of a scripting language which you probably already know: JavaScript.
You can download the sample job file from here. This file was created in PDI 4.4 stable, which means that you should only open it in PDI 4.4 or newer.