






Thursday, 12 September 2013
Tuesday, 27 August 2013
When using the Pentaho PostgreSQL Bulk Loader step, you might come across following error message in the log:
INFO 26-08 13:04:07,005 - PostgreSQL Bulk Loader - ERROR {0} ERROR: invalid byte sequence for encoding "UTF8": 0xf6 0x73 0x63 0x68
INFO 26-08 13:04:07,005 - PostgreSQL Bulk Loader - ERROR {0} CONTEXT: COPY subscriber, line 2
Now this is not a problem with Pentaho Kettle, but quite likely with the default encoding used in your Unix/Linux environment. To check which encoding is currently the default one, execute the following:
$ echo $LANG
en_US
In this case, we can clearly see it is not an UTF-8 encoding, the one which the bulk loader relies on.
So to fix this, we just set the LANG variable in example to the following:
$ export LANG=en_US.UTF-8
Note: This will only be available for the current session. Add it to ~/.bashrc or similar to have it available on startup of any future shell session.
Run the transformation again and now you will see that the process just works flawlessly.
Sunday, 25 August 2013
Part one provided an introduction to Pentaho Kettle routing. This follow-up article will take a look at an additional example, which will retrieve an input value for the condition from a database. This input value could be in example the result of a query which checks in a database logging table if a certain job has been executed successfully: 
The usage of the Evaluate rows number in a table job entry is a bit of a hack here: Our query will always return a result, so this will always be true. But this job entry allows the result set to be passed on to the next one. This saves us from writing a dedicated transformation for this purpose: 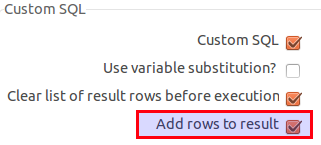
The setup of the Simple evaluation job entry is quite simple ... just reference the return field from the previous job entry: 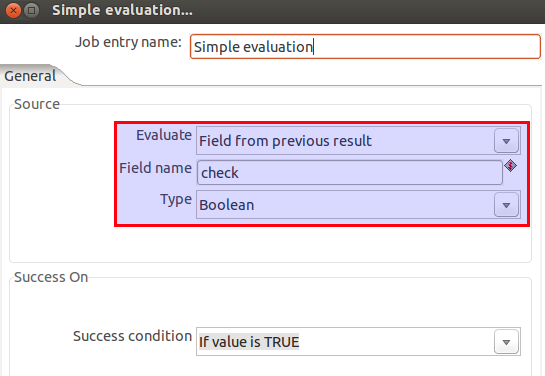
You can download this example here.Saturday, 10 August 2013
Going Agile: Sqitch Database Change Management
You have your database scripts under a dedicated version control and change management system, right? If not, I recommend doing this now.While there have been handful of open source projects around which focus on DB script versioning and change management control, none has really gained a big momentum and a lot of them are dormant. But there is a new player on the ground! A light at the end of the db change management tunnel - so to speak. David Wheeler has been working on Sqitch over the last year and the results are very promising indeed! Currently the github projects shows 7 other contributors, so let’s hope this project gets a strong momentum! Also a new github project for a Sqitch GUI was just founded.
Why I like Sqitch:- You can run all the commands from the command line and get very good feedback.
- Everything seems quite logical and straightforward: It’s easy to get to know the few main commands and in a very short amount of time you are familiar with the tool.
- You can use your choice of VCS.
- It works very well.
Supported DBs are currently MySQL, Oracle, SQLite and PostgreSQL. CUBRID support is under way.
So what do we want to achieve? So what do we want to achieve?
Bring all DDL, stored procedures etc under version control. This is what Git is very good for (or your choice of CVS).
Keep track of the (order of) changes we applied to the database, verify that they are valid, be able to revert them back to a specific state if required. Furthermore, we want to deploy these changes (up to a specific state) to our test and production databases. This is was Sqitch is intended for:

The below write-up are my notes partially mixed with David’s ones.
You can run all the commands from the command line and get very good feedback.
Everything seems quite logical and straightforward: It’s easy to get to know the few main commands and in a very short amount of time you are familiar with the tool.
You can use your choice of VCS.
It works very well.
So what do we want to achieve? So what do we want to achieve?
Bring all DDL, stored procedures etc under version control. This is what Git is very good for (or your choice of CVS).
Keep track of the (order of) changes we applied to the database, verify that they are valid, be able to revert them back to a specific state if required. Furthermore, we want to deploy these changes (up to a specific state) to our test and production databases. This is was Sqitch is intended for:
Bring all DDL, stored procedures etc under version control. This is what Git is very good for (or your choice of CVS).
Keep track of the (order of) changes we applied to the database, verify that they are valid, be able to revert them back to a specific state if required. Furthermore, we want to deploy these changes (up to a specific state) to our test and production databases. This is was Sqitch is intended for:

Info
Forum:
Installation
Options:PostgreSQL: cpan App::Sqitch DBD::Pg (You also have to have PostgreSQL server installed)SQLite: cpan App::Sqitch DBD::SQLiteOracle: cpan App::Sqitch DBD::Oracle (You also have to have SQL*Plus installed)MySQL: cpan App::Sqitch
If you want to have support for i.e. PostgreSQL and Oracle you can just run:PostgreSQL: cpan App::Sqitch DBD::Pg DBD::Oracle
Below I will only discuss the setup for PostgreSQL.
On the terminal run:$ sudo cpan App::Sqitch DBD::Pg
During installation it will ask you for the PostgreSQL version. If you are not sure, run:$ psql --version
It then asks you for a PostgreSQL bin directory. On Ubuntu, this is located in:/usr/lib/postgresql/9.1/bin
Next it will ask you where the PostgreSQL include directory is located. You can find this out by running the following:$ pg_config --includedir
If you don’t have pg_config installed, run first:$ sudo apt-get install libpq-dev
The include location of Ubuntu should be:/usr/include/postgresql
Once installation is finished, check out the man page:$ man sqitch
Within your git project directory, create a dedicated folder:$ mkdir sqitch$ git add .$ cd sqitch$ sqitch --engine pg init projectname
Let's have a look at sqitch.conf:$ cat sqitch.conf
Now let’s add the connection details:$ vi sqitch.conf
uncomment and specify:[core "pg"] client = psql username = postgres password = postgres db_name = dwh host = localhost port = 5432 # sqitch_schema = sqitch
If psql is not in the path, run:$ sqitch config --user core.pg.client /opt/local/pgsql/bin/psqlAdd your details:
$ sqitch config --user user.name 'Diethard Steiner'
Let’s add some more config options: Define the default db so that we don’t have to type it all the time:$ sqitch config core.pg.db_name dwhLet's also make sure that changes are verified after deploying them:$ sqitch config --bool deploy.verify true$ sqitch config --bool rebase.verify true
Check details:cat ~/.sqitch/sqitch.conf
Have a look at the plan file. The plan file defines the execution order of the changes:$ cat sqitch.plan
$ git add .$ git commit -am 'Initialize Sqitch configuration.'
Add your first sql script/change:$ sqitch add create_stg_schema -n 'Add schema for all staging objects.'Created deploy/create_stg_schema.sqlCreated revert/create_stg_schema.sqlCreated verify/create_stg_schema.sql
As you can see, Sqitch creates deploy, revert a verify files for you.
$ vi deploy/create_stg_schema.sql
Add:CREATE SCHEMA staging;
Make sure you remove the default BEGIN; COMMIT; for this as we are just creating a schema and don’t require any transaction.
$ vi revert/create_stg_schema.sql
Add:DROP SCHEMA staging;
$ vi verify/create_stg_schema.sql
Add:SELECT pg_catalog.has_schema_privilege('staging', 'usage');
This is quite PostgreSQL specific. For other dbs use something like this:SELECT 1/COUNT(*) FROM information_schema.schemata WHERE schema_name = 'staging';
Now test if you can deploy the script and revert it:
Try to deploy the changes:The general command looks like this:$ sqitch -d <dbname> deploy
As we have already specified a default db in the config file, we only have to run the following:$ sqitch deployAdding metadata tables to dwhDeploying changes to dwh + create_stg_schema .. ok
Note the plus sign in the feedback which means this change was added.
When you run deploy for the very first time, Sqitch will create maintenance tables in a dedicated schema automatically for you. These tables will (among other things) store in which “version” the DB is.
Check the current deployment status of database dwh:$ sqitch -d dwh status# On database dwh# Project: yes# Change: bc9068f7af60eb159e2f8cc632f84d7a93c6fca5# Name: create_stg_schema# Deployed: 2013-08-07 13:01:33 +0100# By: Diethard Steiner <diethard.steiner@>
To verify the changes run:$ sqitch -d dwh verifyVerifying dwh * create_stg_schema .. okVerify successful
To revert the changes the the previous state, run:$ sqitch revert --to @HEAD^ -y
Side noteYou can use @HEAD^^ to revert to two changes prior the last deployed change.
To revert everything:$ sqitch revertRevert all changes from dwh? [Yes] Yes - create_stg_schema .. ok
To revert back to a specific script (you can also revert back to a specific tag):$ sqitch revert create_dma_schemaRevert changes to create_dma_schema from dwh? [Yes]
Let’s inspect the log:$ sqitch log
Note that the actions we took are shown in reverse chronological order, with the revert first and then the deploy.
Now let's commit it.$ git add .$ git commit -m 'Added staging schema.'
Now that we have successfully deployed and reverted the current change, let’s deploy again:$ sqitch deployLet’s add a tag:$ sqitch tag v1.0.0-dev1 -n 'Tag v1.0.0-dev1.'
Deployment to target DBsSo if you want to deploy these changes to your prod DB in example, you can either do it like this:$ sqitch -d <dbname> -u <user> -h <host> -p <port> deploy (Important: If you are working with PostgreSQL, make sure you add your password to ~/.pgpass and then comment the password out in sqitch.conf beforehand otherwise this will not work.)Or bundle them up, copy the bundle to your prod server and deploy it there:$ sqitch bundleDistribute the bundleOn the prod server:$ cd bundle$ sqitch -d dwhprod deploy
Using Sqitch with an existing project (where some ddl already exists)
Sometimes you take over a project and want to bring the existing DDL under version control and change management.
Thanks to David for providing details on this:
The easiest option is to export the existing DDL and store it in one deploy file. For the revert file you could use a statement like this then:
DROP $schema CASCADE;
Let’s assume we call this change “firstbigchange”:
The first time you do a deploy to the existing database with Sqitch, do it twice: once with --log-only to apply your first big change, and then, from then on, without:
$ sqitch deploy --log-only --to firstbigchange $ sqitch deploy --mode change
The --long-only option has Sqitch do everything in the deploy except actually run deploy scripts. It just skips it, assumes it worked successfully, and logs it. You only want to do this --to that first big dump change, as after that you of course want Sqitch to actually run deploy scripts.
Using more than one DB
DS: Currently it seems like there is a Sqitch version for each of these dbs. What if I was working on a project that used two different dbs installed on the same server and I wanted to use Sqitch for both of them (especially for dev I have more than one db installed on the same server/pc)?
DW: You can have more than one plan and accompanying files in a single project by putting them into subdirectories. They would then be effectively separate Sqitch projects in your SCM. The sqitch.conf file at the top can be shared by them all, though, which is useful for setting up separate database info for them ([core.pg] and [core.mysql] sections, for example).
If you are starting a new project, you would do it like this:
$ sqitch --engine pg --top-dir pg init myproject $ sqitch --top-dir mysql init myproject
Then you have sqitch.plan, deploy, revert, and verify in pg/, and sqitch.plan deploy, revert, and verify in mysql/. To add a new change, add it twice:
$ sqitch --top-dir pg add foo $ sqitch --top-dir mysql add foo
Subscribe to:
Posts (Atom)






