One of my blog's readers just asked me quite an interesting question: How can I show the parameter display name in my Pentaho report if it is different from the parameter value?
Note: Just to clarify, the scenario covered here is when the parameter value and display name are different. So in example when you set the parameter value on an id field and the name on the descriptive field. Because if parameter value and display name are set to the same field, then you can simply drag and drop the parameter name onto your report.
So in our case we defined a parameter called PARAM_OFFICECODE. We set the Parameter Value to OFFICECODE (which happens to be an id) and the Parameter Display Name is set to CITY. We want to use the OFFICECODE to constrain the result set of our main report query (in our case this works better because there happens to be an index on this database table column).
In the report we would like to show in the header the selected office name (CITY) ... but how do we do this? We can not just simply drag and drop the PARAM_OFFICECODE element onto the report header, because it would only display the id (OFFICECODE) and not the display name (CITY).
So in our case we defined a parameter called PARAM_OFFICECODE. We set the Parameter Value to OFFICECODE (which happens to be an id) and the Parameter Display Name is set to CITY. We want to use the OFFICECODE to constrain the result set of our main report query (in our case this works better because there happens to be an index on this database table column).
In the report we would like to show in the header the selected office name (CITY) ... but how do we do this? We can not just simply drag and drop the PARAM_OFFICECODE element onto the report header, because it would only display the id (OFFICECODE) and not the display name (CITY).
You might think there should be an easy solution to this … and right you are. It’s just not as easy as it could be, but quite close …
So I quickly put together a bare bone example (don’t expect any fancy report layout … we just want to see if we can solve this problem):
Our parameter:
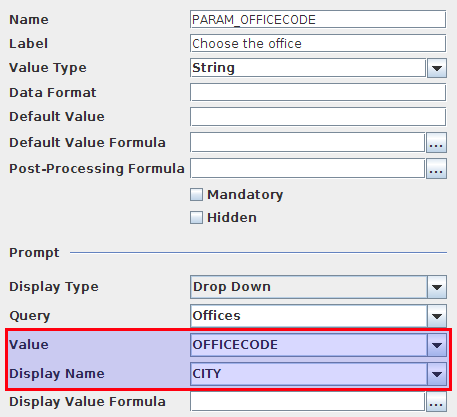
So if we placed this parameter element on the main report, we would just see the OFFICECODE when we ran the report. So how do we get the display name?
- If it is possible to access the name field (in our case CITY) via the SQL query, we could change our main report SQL query and add it there as a new field. But this is not very efficient, right?
- We could create a new query which takes the code/id (in our case OFFICECODE) as a parameter and returns the name (CITY) and then run this query in a sub-report which could return the value to the main report (this is in fact what you had to do some years back). Well, not that neat either.
- Here comes the savior: The SINGLEVALUEQUERY formula function. You can find this one in the Open Formula section. Thomas posted some interesting details about it on his blog some time ago.
Basically for a very long time we had the restriction that we could only run one query to feed data to our report. With the SINGLEVALUEQUERY and MULTIVALUEQUERY formula functions you can run additional queries and return values to the main report.
So here we go … to retrieve the display value:
- We create an additional query called ds_office_chosen which is constrained by the code/id and returns the (display) name: SELECT city AS office_chosen FROM offices WHERE officecode = ${param_officecode}
- We create a new formula element called formula_office_chosen and reference the query ds_office_chosen: =SINGLEVALUEQUERY("ds_office_chosen")
- We can now use formula_office_chosen in our report:
Once this is set up, we can run the report and the display name of the chosen parameter value will be shown: