Pentaho Data Integration (Kettle): Supplying Kettle Variables to Shell Scripts
Tutorial Details
Hence, use the shell job entry only in situation when Kettle doesn't offer the functionality as a step/job entry.
Keeping this in mind, we will create a transformation that supplies a folder name to a shell script and the shell script will then create a folder with exactly this name.
InfiniDB is one of the more popular column oriented database. Currently Kettle doesn't have a dedicated Infinidb bulk upload step. The fastest way to load data into InfiniDB is to use their command line utility called cpimport. Cpimport only accepts job information in the form an xml file, which can be generated with colxml utility . Both cpimport and colxml reside in a sub-directory of the main InfiniDB installation and are usually only executable by the root user. In a nutshell, you tell colxml in which database (optionally table, what kind of delimiter, etc) you want your data file to be loaded and it spits out a nicely formated xml file which cpimport uses to process the data.
 The flow is as follows:
The flow is as follows:
As you can see, Kettle really offers powerful functionality. The important point is to keep in mind to only use shell scripts in cases when Kettle doesn't provide a dedicated step or job entry.
Tutorial Details
- Software: PDI/Kettle 4.1 (download here)
- Knowledge: Intermediate (To follow this tutorial you should have good knowledge of the software and hence not every single step will be described)
- OS: Linux or Mac OS X
- Tutorial files can be downloaded here
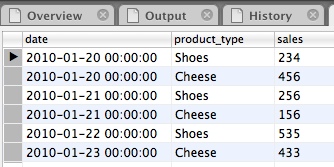
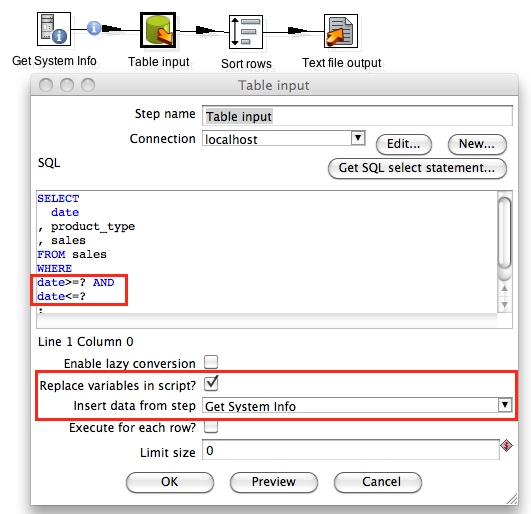
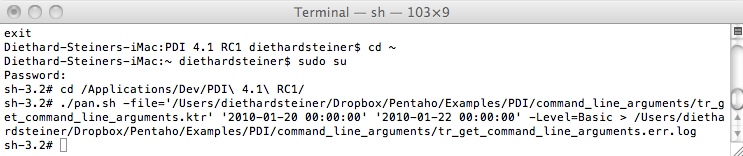
Last time we had a look at Supplying command line arguments to Kettle. This time we take a look at supplying Kettle variables to the command line or shell scripts.
We will start this tutorial with a very general example (so that everybody can set it up) and in the second of half we will focus on a quite specific implementation.
Before we start, we should evaluate the situation. With shell scripts comes huge power in regards to what you can achieve with it. It's easy to fall into temptation and make use of this power, but is it to the benefit of your ETL process?
My advice is to do as much as possible with the dedicated transformation steps and job entries (file and folder management, etc). The reasons are the following (to mention some of the most important ones):
- Steps are in most cases OS independent. Shell scripts are OS dependent.
- Designing everything within one application (how easy is it to understand what each dedicated step does in contrast to writing custom code)
- Easier maintenance
Hence, use the shell job entry only in situation when Kettle doesn't offer the functionality as a step/job entry.
A simple example
The intention of this example is that you can set it up easily and quickly learn how to pass on variables to a shell script. I strongly advice not to use this example in your real world ETL job but to use the dedicated Kettle job entry instead.Keeping this in mind, we will create a transformation that supplies a folder name to a shell script and the shell script will then create a folder with exactly this name.
Now there are two ways to specify a script for the "Execute a shell script" job entry. One way is to insert the script directly in the job entry properties, but this approach doesn't allow you to specify any variables. To use variables, you have to create a dedicated shell file and reference it in the job entry properties.
- Open Spoon (Kettle) and create a new job
- Save the job as jb_supply_var_to_shell_script_simple in a convenient folder.
- Open the Terminal and navigate to the same folder. Create a file called create_folder.sh using vi:
$ vi create_folder.shNote: If you create the shell file on a Windows environment and then copy it over to a Linux environment, make sure that you first get rid of the control characters in the file. One utility which can help you with this is dos2unix. If you don't have it installed, use your favourite package manager (i.e. $ yum install dos2unix) to install it. Once it is installed, run:
dos2unix create_folder.sh - Insert the following (Press i to insert):
mkdir $1
$1 references the first parameter that is supplied via the command line to the shell script. - Make the file executable:
$ chmod a+x create_folder.sh - Go back to Kettle and drag and drop a Start and Execute a shell script job entry onto the canvas
- Create a hop between these job entries
- We will now set up the folder name variable and specify a default value. Press CTRL+J to call the Job Properties dialog. Click on the Parameters tab and specify VAR_FOLDER_NAME as a parameter as test as default value. Click OK.
- Double click on the Execute a shell script job entry
- Click on the Script file name input field; then press CTRL+Space and choose the internal job filename directory. Click Browse and choose the shell file we just created. Note: Mac OS X users - the short cut doesn't work, because CTRL+Space is reserved for Spotlight. Either you disable the shortcut or you manually write the variable name.
- For the Working directory specify the internal job filename directory variable as well.
- In the Fields section supply the ${VAR_FOLDER_NAME} variable.
- Save the job and execute it. If you take a look at your folder, you will see that a new subfolder named "test" was created.
Kettle / InfiniDB Series: Using Kettle JDNI details with colxml
Although I make an attempt to provide some basic information below, I recommend reading my tutorial Pentaho Data Integration and Infinidb Series: Bulk Upload to get some more information about Infinidb.This will help understand this section better.
InfiniDB is one of the more popular column oriented database. Currently Kettle doesn't have a dedicated Infinidb bulk upload step. The fastest way to load data into InfiniDB is to use their command line utility called cpimport. Cpimport only accepts job information in the form an xml file, which can be generated with colxml utility . Both cpimport and colxml reside in a sub-directory of the main InfiniDB installation and are usually only executable by the root user. In a nutshell, you tell colxml in which database (optionally table, what kind of delimiter, etc) you want your data file to be loaded and it spits out a nicely formated xml file which cpimport uses to process the data.
Now all this is an ideal candidate for the Execute a shell script job entry, because Kettle doesn't provide this functionality out of the box (yet).
Now that we all know how the process works, let's focus on our ETL process. If somebody wants to follow this section, you can download an open source version of Infinidb here (you can find detailed installation instructions on the same website).
If you are working with a lot of ETL files it is recommended to use JNDI connection details to make the maintenance easier. So instead of specifying all the database connection details for every step that requires them, we can simple store all our database connection details in the simple-jndi/jdbc.properties file, assign a name to each connection and reference this name in the Kettle step. So in the case that the database connection details change, you only have to change them in one place (namely the jdbc.properties file) and not in all Kettle steps. In our example, we will follow this approach.
The only tricky bit here is that colxml requires the database name. Kettle has actually a dedicated Properties Input step (thanks to Slawo for pointing this out) which allows you to read the jdbc.properties file and with a bit of string manipulation we can extract the database name.
For the example below to work you have create a table called fact_impression on a Infinidb database, have a working transformation that outputs a pipe separated file called fact_impression.tbl which we can bulk upload to the fact_impression table. Moreover, you have to define the database connection details in {KETTLE_ROOT}/simple-jndi/jdbc.properties.
Now let's get started. I will only describe the main points. Please find below an overview of the job:
- We provide two parameters to this job: ${VAR_DWH} which is the JNDI name we want to use for our ETL job and ${VAR_ETL_FILE} which is unsurprisingly the name of the main ETL transformation that we want to use in this job. Press CTRL+J to see the job properties. Click on the Parameters tab to see these defined parameters. The idea is that these parameters are supplied on the command line when kitchen.sh is called (see Supplying command line arguments to Kettle for more details).
- The tr_get_jndi_properties transformation reads the jdbc.properties file and extracts all the database connection details for the JDNI name defined in ${VAR_DWH}. To achieve this we use some regular expressions (this technique is described in my Using Regular Expressions with Pentaho Data Integration tutorial). Note that at the end of this transformation we define the database name as a variable (dwh_database).
- All data files for bulk upload have to be stored in /usr/local/Calpont/data/bulk/data/import. In this case we are a bit cautious and delete any old *.tbl file in this directory.
- We execute our main ETL transformation (the filename is defined in ${VAR_ETL_FILE}). This transformation has to output a CSV file with the name fact_impression.tbl into /usr/local/Calpont/data/bulk/data/import. Make sure it is pipe delimited.
- The next step prepares the Infinidb job file. The infinidb_colxml.sh Shell script job entry calls the external shell file infinidb_colxml.sh. This shell file includes the following:
rm -rf /usr/local/Calpont/data/bulk/job/Job_9991.xml
[ -f /usr/local/Calpont/data/bulk/data/import/fact_impression.tbl ] && /usr/local/Calpont/bin/colxml $1 -j 9991 -t fact_impression
This shell script basically deletes an existing Infinidb job file and if fact_impression.tbl (this is the CSV output file of our main transformation) exists it will create a new Infinidb job file. Please find all the details about this in my tutorial Pentaho Data Integration and Infinidb Series: Bulk Upload. As you can see we define an argument $1 (highlighted in yellow in the above shell script). $1 will basically accept the first parameter supplied by Kettle, which is dwh_database. Hence the order in which you specify the arguments in the Shell script job entry is really important.
Note that we define dwh_database variable as an argument in the Shell script job entry. - The Load Tables Shell script step calls cpimport and initiates a bulk upload.
- The last step is not really necessary, but here we delete all data files again in the bulk upload directory.
As you can see, Kettle really offers powerful functionality. The important point is to keep in mind to only use shell scripts in cases when Kettle doesn't provide a dedicated step or job entry.
If you want to learn more about Shell scripting, consider this free book.