





Kettle: Handling Dates with Regular Expression
This is the second tutorial that focuses on using regular expressions with Pentaho Kettle (PDI). This is again a demonstration on how powerful regular expression acutally are.
In this example we are dealing with a simplified data set containing date values. The problem is, that the date doesn't have a standard format. We have following values:
date
2010/1/2
2010/01/2
2010/1/02
2010/01/02
20100102
We assume for now, that all follow at least this basic standard: year, month, day. Now, we need to somehow generate a standard date in the format yyyy-MM-dd using the value from the date field as input.
Regular expressions are of much help here, as we can use the concept of capturing groups. Capturing groups will allow us to retrieve the year, month and day parts of the date easily, then we build together our final date (we want it in the yyyy-MM-dd format). Now let's see how this is done:
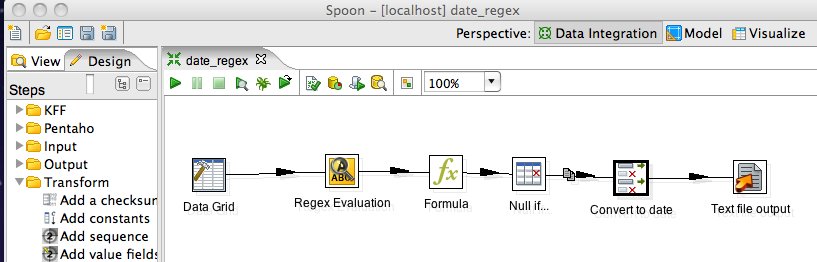
For our convenience, we use the data grid step to store our dummy dates for testing:
Now we are ready to go ahead and work on our regular expression. Insert the Regex Evaluation step from the Scripting folder and configure it as shown in the screenshot below:
On the content tab make sure that you select "Permit whitespace and comments in pattern". Now let's have a look at the regular expression:
- The string must start with 4 numbers. We enclose the definition by brackets to create the first capturing group. Note: I added #1. This is a comment and helps to mark the capturing groups for easy reference.
- Next we say that a dash can follow or not. This is our 2nd capturing group.
- I guess you get the idea for the remaining capturing groups. In the end we make sure that nothing else follows, hence we use the dollar sign.
Once we have created our capturing groups, we can reference them in the "Capture Group Fields". First make sure that "Create fields from capture" is activated. Then fill out the fields below as shown.
This step will basically get the year, month and day parts.
Now we have to build the date together. We can use the formula step therefore:
First we check if a value exists, if not, we set the field to 0s. In case a value exists, we check if the month and day part have a leading zero, if not, we add it. Finally, we build the whole date string together.
Now, it is not a very good approach to save non standard 0000-00-00 dates in the database (i.e.), hence we use the "Null if ..." step to set records with 0000-00-00 date to null:
The final step left to do is to convert the string to a proper date. You can do this with the "Select values" step. Go to the Meta-data tab and fill it out as shown below:
Save the transformation and run it. Now let's have a look at the output:
You can see that it is quite simple to handle non standardized data with regular expressions. You can download the transformation here.










